
Keynote speech di Pierluigi Coppola a Data Mobility 2025
Trasformare i big data in servizi di mobilità.
Esempi, modelli e applicazioni concrete
I big data hanno ormai conquistato buona parte del dibattito sui metodi innovativi di raccolta e analisi dei dati nel campo della mobilità, ma quali sono le applicazioni concrete che permettono di utilizzarli per nuove politiche della mobilità e servizi di trasporto? Nel suo keynote speech al Data Mobility Summit 2025, Pierluigi Coppola, professore ordinario di Pianificazione dei Trasporti al Politecnico di Milano, ci ha accompagnato lungo le nuove frontiere della modellazione della domanda e dell’analisi dei dati, mostrando come l’integrazione tra tecnologia, machine learning e conoscenza dei fenomeni sociali possa trasformare dati grezzi in pratiche innovative di mobilità sostenibile. Dalle Smart App, ai modelli activity-based fino al nudging per il cambio dei comportamenti, il suo intervento ci invita a ripensare le strategie di raccolta, validazione e utilizzo dei dati, e a investire su strumenti e competenze capaci di cogliere la complessità della realtà.
Orientarsi nell’universo dei big data
I big data oggi riguardano diversi settori della mobilità urbana ed extraurbana, integrandosi e sostituendosi alle tradizionali tecniche di rilevamento e osservazione dei fenomeni di mobilità urbana. Dalle Smart Card alle videocamere o termocamere per il monitoraggio dei flussi di persone negli spazi pubblici, fino a tecniche più sofisticate che includono la raccolta di dati telefonici e la comunicazione tra veicoli e smartphone, abilitando lo sviluppo di modelli avanzati, politiche innovative e nuovi servizi di mobilità.
Ma come è possibile classificare il vasto universo dei big data? Una prima distinzione è tra dati aggregati e dati disaggregati.
I big data aggregati riguardano principalmente i flussi di traffico, rilevati con le tecnologie che oggi hanno sostituito i tradizionali conteggi di traffico a bordo strada: smart card, FCD (floating car data provenienti dispositivi di monitoraggio installati nelle auto a fini assicurativi), dati telefonici. «Per questioni di privacy, l’uso che si può fare di questi dati è solamente aggregato: quando si scende al di sotto di una numero minimo di osservazioni che condividono la stessa origine e destinazione, si ricorre al cosiddetto mascheramento, con cui il dato viene oscurato per non essere riconducibile ad un singolo individuo». Questi dati permettono di svolgere analisi avanzate sia statiche che dinamiche, così come analisi di clustering, di flussi e traiettorie dei veicoli, molto utili a capire l’andamento dei flussi di mobilità nel tempo (Ad es. in una giornata) ed aggiornare le matrici O/D.

I dati disaggregati, invece, permettono di studiare i comportamenti di mobilità: «Le tradizionali survey basati su questionari all’utente, oggi sono sostituite da Smart App e travel diaries, che riescono a monitorare in maniera automatica e diretta i comportamenti delle persone». Non solo gli spostamenti di origine e destinazione, ma anche la durata della sosta, il modo di trasporto utilizzato, o l’attività in destinazione, grazie ad algoritmi sofisticati per il riconoscimento automatico di questi aspetti.
Le applicazioni smart si distinguono a loro volta tra supervised e unsupervised, in base al tipo di interazione con il possessore dello smartphone (se diretta o assente).
L’applicazione supervised, quindi con interazione diretta, pur avendo diversi vantaggi, ha dei costi dovuti dalla necessità di validazione e azione da parte dell’utente. In compenso oggi, tramite algoritmi di machine learning e clustering, le applicazioni unsupervised sono in grado di ricavare informazioni individuali senza ricorrere all’interazione con l’utente. «Ad esempio, si possono utilizzare tecniche di hierarchical clustering e DBSCAN per ricavare il motivo dello spostamento dalle caratteristiche dei luoghi di destinazione dell’area di studio, dalla periodicità degli spostamenti e dalla durata della sosta. Altre applicazioni sono in grado di riconoscere automaticamente il modo con cui si viaggia in funzione, ad esempio, della velocità dello spostamento». In tutti questi casi si parla di “enhanced unsupervised learning”, cioè tecniche basate sul machine learning di dati ricorrenti, anche anonimi, da cui si riescono a carpire informazioni sull’individuo e su come si sta spostando.
Entriamo nel merito: il Supervised Learning
Secondo il prof. Coppola, la frontiera è rappresentata dal supervised learning, ovvero da quelle applicazioni che permettono di avere un feedback di validazione da parte dell’utente sulle caratteristiche dello spostamento stimate attraverso gli algoritmi, come il modo di trasporto, il motivo o le attività svolte a destinazione; ciò consente di associare il dato di mobilità ad un profilo utente.
Questo tipo di approccio incontra due tipi di barriere: da un lato la resistenza delle persone a fornire il consenso al tracciamento dei propri spostamenti per periodi di tempo prolungati; dall’altro la necessità che l’app sia costantemente attiva sul telefono e connessa alla rete.
Ma quali sono le potenzialità di questo metodo? In primis, il supervised learning attraverso l’interazione diretta con gli utenti, consente di raccogliere informazioni sulla mobilità giornaliera (“travel diaries”) che permettono lo sviluppo di activity-based model, «un approccio modellistico nato negli anni ‘80 a scopi di ricerca, ma mai realmente applicato proprio per la difficoltà di avere sufficienti dati a disposizione. Oggi questi modelli stanno tornando di attualità grazie alla disponibilità di travel diaries a costi relativamente bassi».
Gli activity-based model sono modelli di domanda più avanzati dei tradizionali modelli a quattro stadi e permettono di simulare la mobilità giornaliera degli individui valutando l’intera sequenza di attività svolte dall’utente nel corso della giornata e non soltanto riferendosi ad un singolo spostamento origine-destinazione. Come lo fanno? Acquisendo informazioni sulla localizzazione, la durata, e le caratteristiche degli spostamenti tra le diverse attività giornalieri. Sono quindi modelli che permettono di ricostruire le catene di spostamento quotidiane e i bisogni di mobilità che le generano, simulando la domanda di trasporto che deriva dalle diverse attività programmate e svolte dagli gli individui.
L’approccio activity-based: sperimentazioni e difficoltà
Esempi di modelli di tipo activity-based sono sviluppati al Politecnico di Milano e riguardano la frequenza degli spostamenti giornalieri (trip frequency models) o la sequenza di attività primarie e secondarie e il modo di trasporto utilizzato tra un’attività e l’altra.
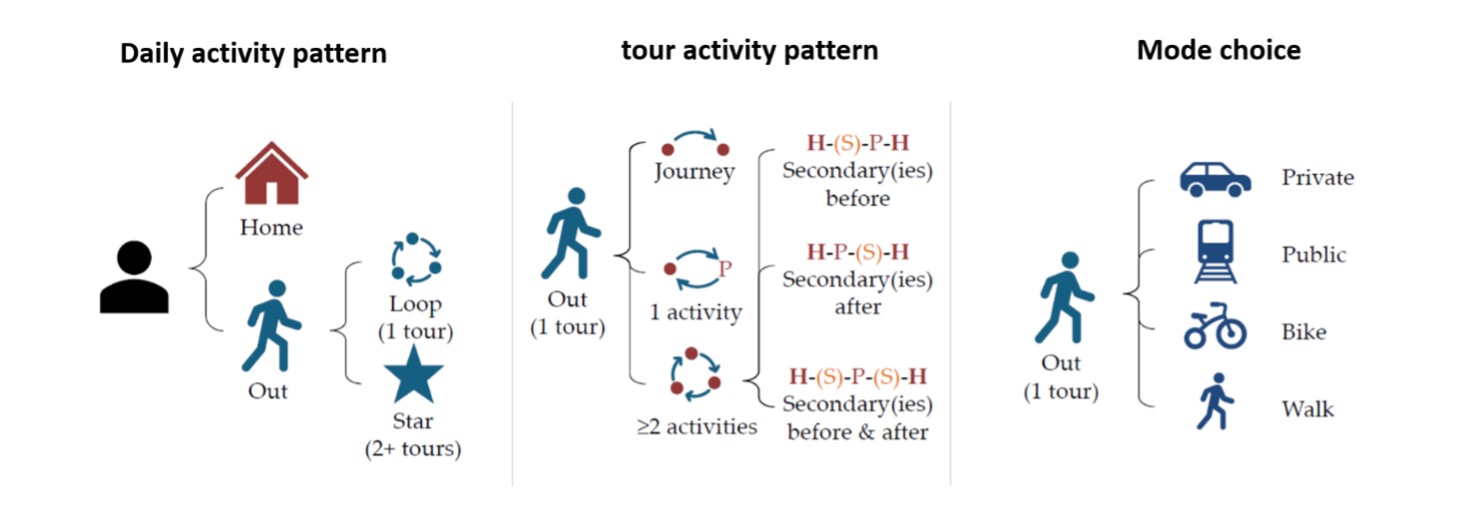
L’ingaggio di un campione di individui sufficientemente ampio ed incline ad installare in background un’app che quotidianamente monitori le proprie attività può rappresentare una criticità. Come si supera questa ritrosia? «In molti casi si ricorre a incentivi monetari e premialità, ma non sempre è sufficiente. In una sperimentazione condotta con gli studenti del Politecnico di Milano, nonostante fosse previsto come incentivo un buono per acquisti da 50€, si è registrato un drop di partecipazione di oltre l’80% tra chi è stato contattato per partecipare alla sperimentazione e chi poi ha effettivamente installato l’app e l’ha utilizzata». Nel corso del tempo, inoltre, la partecipazione subisce un “calo fisiologico” e tende a decrescere.
L’importanza del data processing
A seconda del tipo di analisi e di modello che si intende sviluppare, il dato può essere manipolato, utilizzato, interpretato, e processato diversamente. È quindi fondamentale costruire una base dati corretta e utile per le finalità preposte. Se l’obiettivo è sviluppare dei modelli activity based occorre scartare tutti gli “inner loop trips”, ovvero i brevi spostamenti nel raggio di pertinenza della residenza. Quando si studiano i comportamenti di mobilità di pedoni e ciclisti questi dati diventano invece fondamentali.
Gran parte del lavoro dipende da come i dati grezzi vengono processati: «Un aspetto spesso trascurato che sta risultando sempre più rilevante, e che dipende fortemente dalle finalità di analisi». Il data processing prevede una correzione del dato, specialmente quando non viene validato o supervisionato dall’utente. Un esempio è nell’immagine sottostante, dove si vede uno spostamento tra Brescia e Milano effettuato in ferrovia ma interpretato come viaggio in autostrada perché assegnato alla tratta extraurbana.
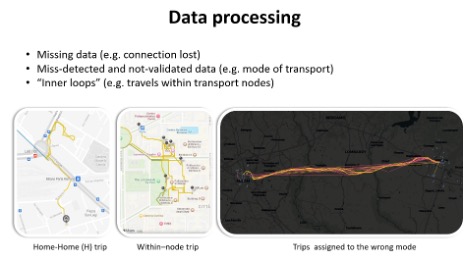
Inoltre, spesso è necessario ridurre la complessità dei travel diaries: monitorare troppe attività porterebbe a una numerosità di combinazioni difficilmente gestibile.
Real time data & nudging: un binomio vincente
Un altro elemento di classificazione dei big data (in particolare quelli provenienti dalle Smart App riguarda la disponibilità nel tempo, ovvero se i dati acquisisti sono disponibili ex post e real time. Questi ultimi possono essere utilizzati oggi non solo per fare analisi in tempo reale, e quindi attuare politiche di controllo della domanda, ma anche e soprattutto per sviluppare e testare politiche innovative.
Un esempio sono il nudging e la gamification, «ovvero delle strategie attuate per incentivare gli utenti con una “spinta dolce” verso comportamenti di mobilità più sostenibili, gratificandoli con gadget, buoni sconto, incettivi monetari, o attraverso lo stimolo della competizione» (ne avevamo parlato qui).
Anche in questi casi l’offerta di incentivi efficaci è cruciale. Uno studio in corso presso il Politecnico di Milano ha dimostrato, da una parte, che senza incentivi la partecipazione alla sperimentazione è scarsa, ma, dall’altra, il nudging e la gamification possono essere efficaci per stimolare una variazione verso comportamenti di mobilità più sostenibili, ad esempio una maggiore tendenza a spostarsi a piedi e in bicicletta. «Si tratta di risultati in linea con la letteratura: senza incentivi monetari o significativi l’impatto è scarso: per attuare politiche di nudging servono risorse». .
Altre politiche innovative: il crowd shipping
Un altro esempio di politiche innovative basate su dati real time è il crowd shipping. Un concetto che sta prendendo piede nei paesi del nord Europa, e che si basa sull’affidamento delle consegne dell’ultimo miglio (pacchetti di piccola dimensione) ai viaggiatori stessi. L’utente si impegna a ritirare il pacchetto presso un locker point e a consegnarlo al destinatario facendo piccole deviazioni dal suo percorso abituale, in cambio di un compenso.
Un studio del Politecnico di Milano mira a stimare la disponibilità da parte degli studenti universitari a partecipare a una pratica di questo tipo, utilizzando i lockers disponibili nel campus universitario. «Si stima che la “willingness to work” come crowdshipper sia intorno a 10€/ora. La partecipazione e la disponibilità dipendono molto dal motivo dello spostamento e dalla fretta di arrivare a destinazione».

What’s next?
In conclusione, le Smart App supervised rappresentano una nuova frontiera per la raccolta dati finalizzata ad analisi di mobilità e ideazione di politiche innovative. Ma è fondamentale migliorare il data processing e la trasformazione del dato grezzo in un database utilizzabile per le analisi e per lo sviluppo di modelli avanzati.
La ricerca in questo settore si sta orientando al miglioramento dei sistemi di raccolta dati e allo sviluppo di algoritmi – anche di intelligenza artificiale – per la migliore identificazione degli spostamenti. Ma le modalità di ingaggio e partecipazione per promuovere la mobilità sostenibile attraverso l’uso di queste applicazioni sono ancora da migliorare e approfondire. «È un tema che va affrontato con opportune misure che incentivino la partecipazione a queste sperimentazioni e l’effettivo utilizzo nella pratica quotidiana».
Iscriviti alla nostra newsletter!
Riceverai ogni mese news, articoli e contenuti selezionati per te dalla nostra redazione.
Data Mobility è un progetto di GO-Mobility
Scopri chi siamo e i progetti con cui trasformiamo i dati in soluzioni di mobilità.
©2026 GO-Mobility s.r.l. | Partita IVA 11257581006